
这篇博文主要从原理和具体实战两个部分对词袋模型进行展开,实战部分包括Python实现和C++实现。
BoW词袋模型原理
模型简介
BoW(Bag of Words)词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。举个例子,有如下两个文档:
文档一:Bob likes to play basketball, Jim likes too.
文档二:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”,8. “games”, 9. “Jim”, 10. “too”}
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
文档一:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
文档二:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(下文中,将用单词的直方图表示)。不过,在构造文档向量的过程中可以看到,我们并没有表达单词在原来句子中出现的次序(这是词袋模型的缺点之一,不过瑕不掩瑜甚至在此处无关紧要)。
为什么要用BoW模型描述图像
SIFT特征虽然也能描述一幅图像,但是每个SIFT矢量都是128维的,而且一幅图像通常都包含成百上千个SIFT矢量,在进行相似度计算时,这个计算量是非常大的,通行的做法是用聚类算法对这些矢量数据进行聚类,然后用聚类中的一个簇代表BoW中的一个视觉词,将同一幅图像的SIFT矢量映射到视觉词序列生成码本,这样每一幅图像只用一个码本矢量来描述,这样计算相似度时效率就大大提高了。
构建BoW码本步骤
- 假设训练集有M幅图像,对训练图象集进行预处理。包括图像增强,分割,图像统一格式,统一规格等等。
- 提取SIFT特征。对每一幅图像提取SIFT特征(每一幅图像提取多少个SIFT特征不定)。每一个SIFT特征用一个128维的描述子矢量表示,假设M幅图像共提取出N个SIFT特征。
- 用K-means对2中提取的N个SIFT特征进行聚类,K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。聚类中心有k个(在BOW模型中聚类中心我们称它们为视觉词),码本的长度也就为k,计算每一幅图像的每一个SIFT特征到这k个视觉词的距离,并将其映射到距离最近的视觉词中(即将该视觉词的对应词频+1)。完成这一步后,每一幅图像就变成了一个与视觉词序列相对应的词频矢量。
- 构造码本。码本矢量归一化因为每一幅图像的SIFT特征个数不定,所以需要归一化。测试图像也需经过预处理,提取SIFT特征,将这些特征映射到为码本矢量,码本矢量归一化,最后计算其与训练码本的距离,对应最近距离的训练图像认为与测试图像匹配。设视觉词序列为{眼睛 鼻子 嘴}(k=3),则训练集中的图像变为:
第一幅图像:[1 0 0]
第二幅图像:[5 3 4]
......
当然,在提取sift特征的时候,可以将图像打成很多小的patch,然后对每个patch提取SIFT特征。
总结一下,整个过程其实就做了三件事,首先提取对n幅图像分别提取SIFT特征,然后对提取的整个SIFT特征进行KMeans聚类得到k个聚类中心作为视觉单词表(或者说是词典),最后对每幅图像以单词表为规范对该幅图像的每一个SIFT特征点计算它与单词表中每个单词的距离,最近的+1,便可得到该幅图像的码本。实际上第三步是一个统计的过程,所以BoW中向量元素都是非负的。Yunchao Gong 2012年NIPS上有一篇用二进制编码用于图像快速检索的文章就是针对这类元素是非负的特征而设计的编码方案。
举两个例子来说明BoW词袋模型。第一个例子在介绍BoW词袋模型时一般资料里会经常使用到,就是将图像类比成文档,即一幅图像类比成一个文档,将图像中提取的诸如SIFT特征点类比成文档中的单词,然后把从图像库中所有提取的所有SIFT特征点弄在一块进行聚类,从中得到具有代表性的聚类中心(单词),再对每一幅图像中的SIFT特征点找距离它最近的聚类中心(单词),做词频(TF)统计,图解如下:
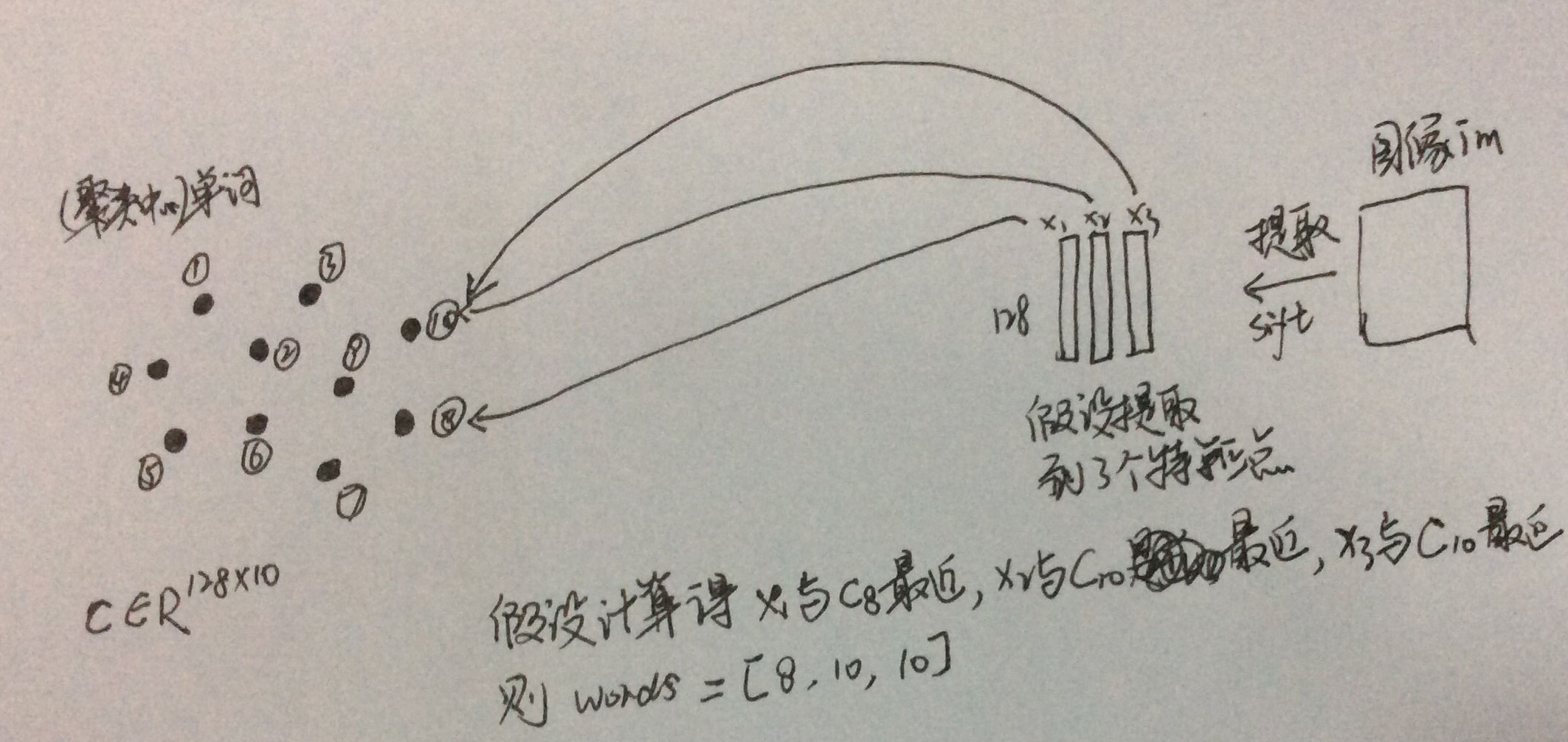
做完词频(TF)统计后,为了降低停用词带来的干扰,可以再算个逆文档词频(IDF),也就是给TF乘上个权重,该过程可以图解如下:
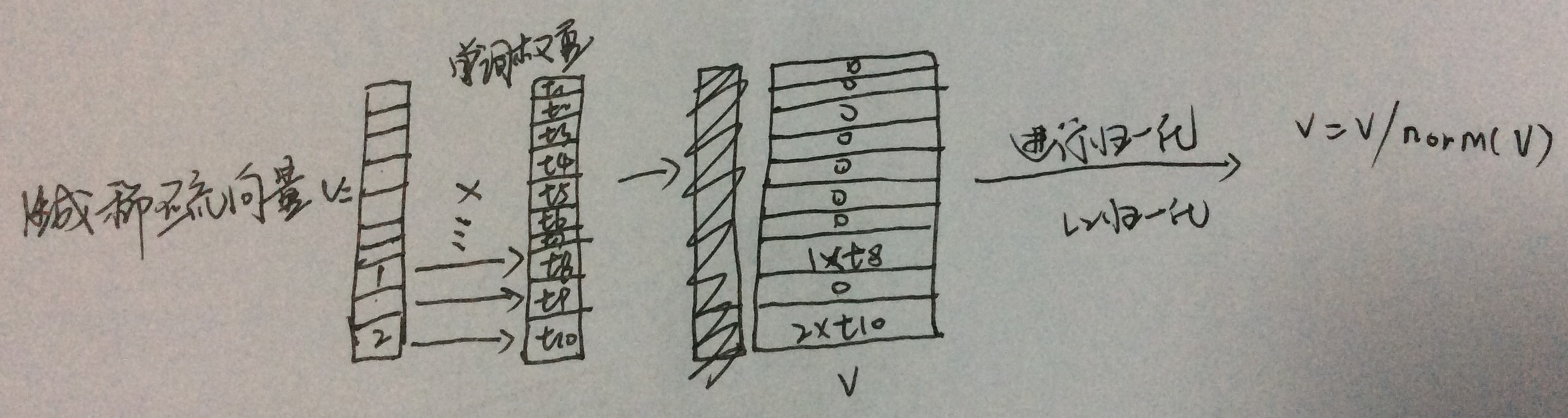
上面单词权重即逆文档词频(IDF),那时通过统计每个单词包含了多少个文档然后按设定的一个对数权重公式计算得来的,具体如下:
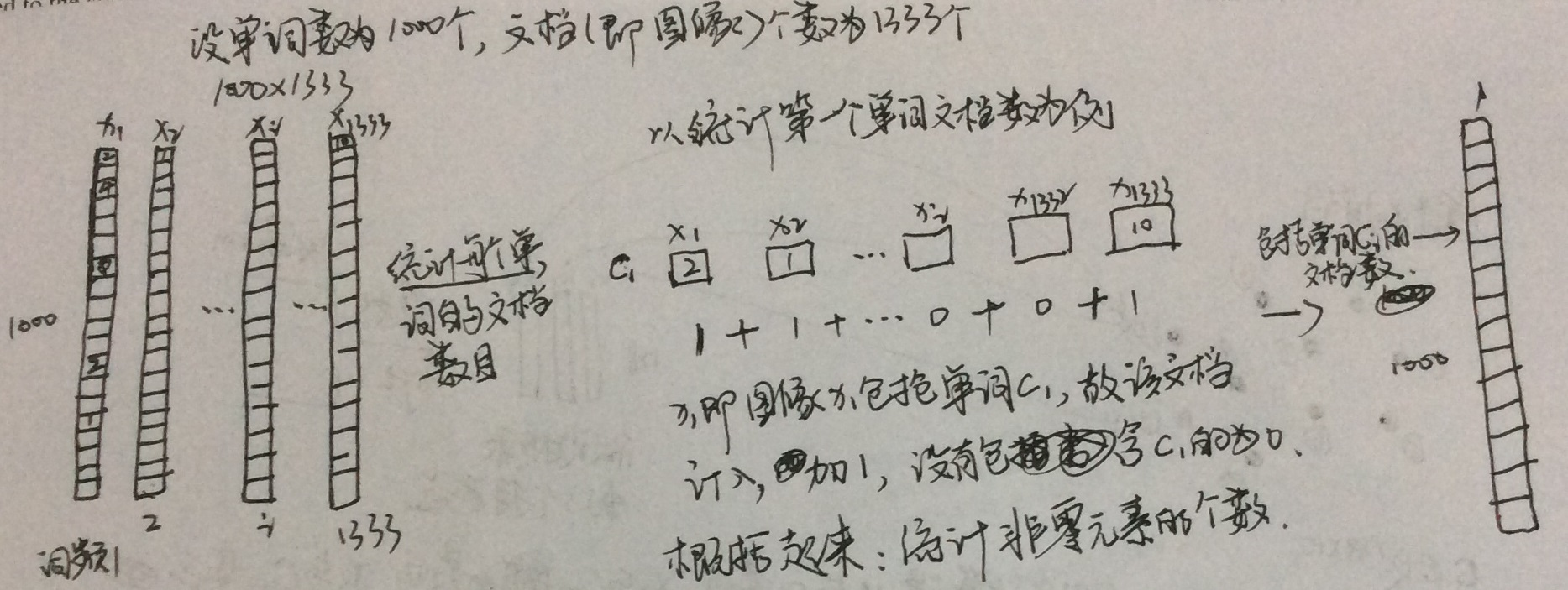
对于上传上来的查询图像,提取SIFT然后统计tf后乘上上面的idf便可得到id-idf向量,然后进行L2归一化,用内积做相似性度量。
在做TF统计的时候,我们知道一般为了取得更好的效果,通常单词数目会做得比较大,动则上万或几十万,所以在做聚类的时候,可以对这些类中心做一个K-D树,这样在做TF词频统计的时候便可以加快单词直方图计算的速度。
上面举的例子对于初次接触BoW的人来说可能讲得不是那么的直观,小白菜可以举一个更直观的例子(虽然有些地方可能会不怎么贴切,但还是触及BoW的本质),比如美国总统全国大选,假设有10000个比较有影响力的人参加总统竞选,这10000个人表示的就是聚类中心,他们最具有代表性(K-means做的就是得到那些设定数目的最具有代表性的特征点),每个州类比成一幅图像,州里的人手里持的票就好比是SIFT特征点,这样的话,我们就可以对每个州做一个10000维的票数统计结果,这个统计出来的就是上面第一个例子里所说的词频向量。另外,我们还可以统计每个竞选人有多少个州投了他的票,那么就可以得到一个10000维长的对州的统计结果,这个结果再稍微和对数做下处理,便得到了所谓的逆文档词频。
BoW词袋模型图像检索Python实战
上面的两个例子应该讲清楚了BoW词袋模型吧,下面就来看看BoW词袋模型用Python是怎么实现的。
#!/usr/local/bin/python2.7
#python findFeatures.py -t dataset/train/
import argparse as ap
import cv2
import numpy as np
import os
from sklearn.externals import joblib
from scipy.cluster.vq import *
from sklearn import preprocessing
from rootsift import RootSIFT
import math
# Get the path of the training set
parser = ap.ArgumentParser()
parser.add_argument("-t", "--trainingSet", help="Path to Training Set", required="True")
args = vars(parser.parse_args())
# Get the training classes names and store them in a list
train_path = args["trainingSet"]
#train_path = "dataset/train/"
training_names = os.listdir(train_path)
numWords = 1000
# Get all the path to the images and save them in a list
# image_paths and the corresponding label in image_paths
image_paths = []
for training_name in training_names:
image_path = os.path.join(train_path, training_name)
image_paths += [image_path]
# Create feature extraction and keypoint detector objects
fea_det = cv2.FeatureDetector_create("SIFT")
des_ext = cv2.DescriptorExtractor_create("SIFT")
# List where all the descriptors are stored
des_list = []
for i, image_path in enumerate(image_paths):
im = cv2.imread(image_path)
print "Extract SIFT of %s image, %d of %d images" %(training_names[i], i, len(image_paths))
kpts = fea_det.detect(im)
kpts, des = des_ext.compute(im, kpts)
# rootsift
#rs = RootSIFT()
#des = rs.compute(kpts, des)
des_list.append((image_path, des))
# Stack all the descriptors vertically in a numpy array
#downsampling = 1
#descriptors = des_list[0][1][::downsampling,:]
#for image_path, descriptor in des_list[1:]:
# descriptors = np.vstack((descriptors, descriptor[::downsampling,:]))
# Stack all the descriptors vertically in a numpy array
descriptors = des_list[0][1]
for image_path, descriptor in des_list[1:]:
descriptors = np.vstack((descriptors, descriptor))
# Perform k-means clustering
print "Start k-means: %d words, %d key points" %(numWords, descriptors.shape[0])
voc, variance = kmeans(descriptors, numWords, 1)
# Calculate the histogram of features
im_features = np.zeros((len(image_paths), numWords), "float32")
for i in xrange(len(image_paths)):
words, distance = vq(des_list[i][1],voc)
for w in words:
im_features[i][w] += 1
# Perform Tf-Idf vectorization
nbr_occurences = np.sum( (im_features > 0) * 1, axis = 0)
idf = np.array(np.log((1.0*len(image_paths)+1) / (1.0*nbr_occurences + 1)), 'float32')
# Perform L2 normalization
im_features = im_features*idf
im_features = preprocessing.normalize(im_features, norm='l2')
joblib.dump((im_features, image_paths, idf, numWords, voc), "bof.pkl", compress=3)
将上面的文件保存为findFeatures.py,前面主要是一些通过parse使得可以在敲命令行的时候可以向里面传递参数,后面就是提取SIFT特征,然后聚类,计算TF和IDF,得到单词直方图后再做一下L2归一化。一般在一幅图像中提取的到SIFT特征点是非常多的,而如果图像库很大的话,SIFT特征点会非常非常的多,直接聚类是非常困难的(内存不够,计算速度非常慢),所以,为了解决这个问题,可以以牺牲检索精度为代价,在聚类的时候先对SIFT做降采样处理。最后对一些在在线查询时会用到的变量保存下来。对于某个图像库,可以在命令行里通过下面命令生成BoF:
python findFeatures.py -t dataset/train/
在线查询阶段相比于上面简单了些,没有了聚类过程,具体代码如下:
#!/usr/local/bin/python2.7
#python search.py -i dataset/train/ukbench00000.jpg
import argparse as ap
import cv2
import imutils
import numpy as np
import os
from sklearn.externals import joblib
from scipy.cluster.vq import *
from sklearn import preprocessing
import numpy as np
from pylab import *
from PIL import Image
from rootsift import RootSIFT
# Get the path of the training set
parser = ap.ArgumentParser()
parser.add_argument("-i", "--image", help="Path to query image", required="True")
args = vars(parser.parse_args())
# Get query image path
image_path = args["image"]
# Load the classifier, class names, scaler, number of clusters and vocabulary
im_features, image_paths, idf, numWords, voc = joblib.load("bof.pkl")
# Create feature extraction and keypoint detector objects
fea_det = cv2.FeatureDetector_create("SIFT")
des_ext = cv2.DescriptorExtractor_create("SIFT")
# List where all the descriptors are stored
des_list = []
im = cv2.imread(image_path)
kpts = fea_det.detect(im)
kpts, des = des_ext.compute(im, kpts)
# rootsift
#rs = RootSIFT()
#des = rs.compute(kpts, des)
des_list.append((image_path, des))
# Stack all the descriptors vertically in a numpy array
descriptors = des_list[0][1]
#
test_features = np.zeros((1, numWords), "float32")
words, distance = vq(descriptors,voc)
for w in words:
test_features[0][w] += 1
# Perform Tf-Idf vectorization and L2 normalization
test_features = test_features*idf
test_features = preprocessing.normalize(test_features, norm='l2')
score = np.dot(test_features, im_features.T)
rank_ID = np.argsort(-score)
# Visualize the results
figure()
gray()
subplot(5,4,1)
imshow(im[:,:,::-1])
axis('off')
for i, ID in enumerate(rank_ID[0][0:16]):
img = Image.open(image_paths[ID])
gray()
subplot(5,4,i+5)
imshow(img)
axis('off')
show()
将上面的代码保存为search.py,对某幅图像进行查询时,只需在命令行里输入:
#python search.py -i dataset/train/ukbench00000.jpg(查询图像的路径)
上面的代码中,你可以看到rootSIFT注释掉了,你也可以去掉注释,采用rootSIFT,但这里实验中我发觉rootSIFT并没有SIFT的效果好。最后看看检索的效果,最上面一张是查询图像,后面的是搜索到的图像:
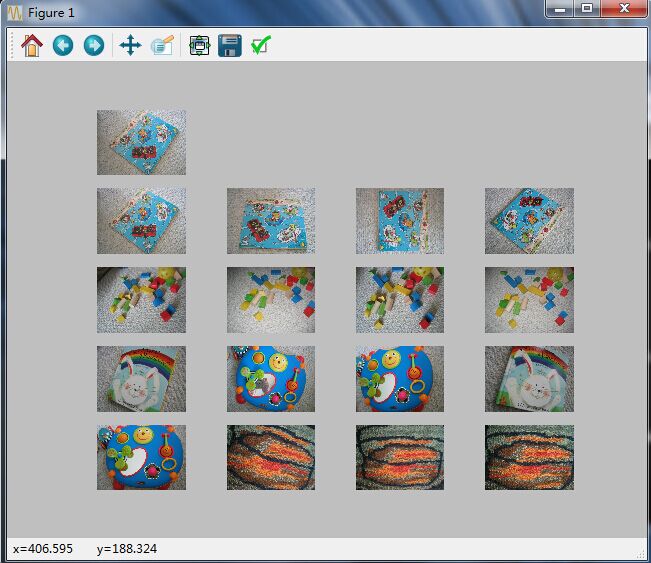
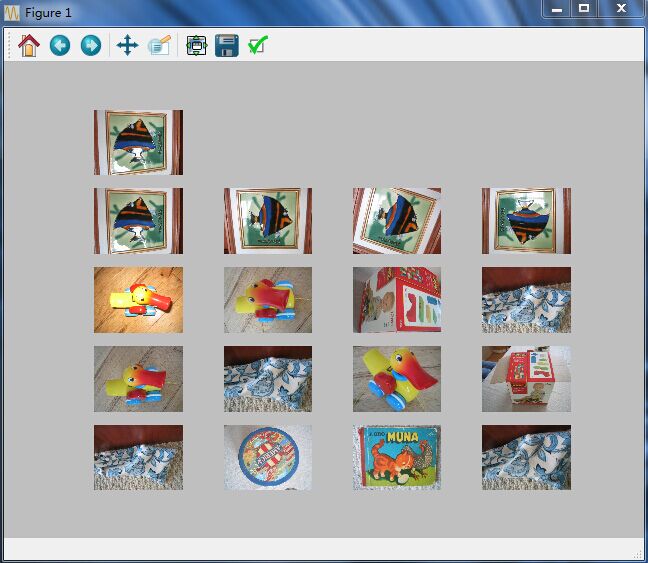
词袋模型图像检索C++实战
整个实战的代码可以在这里下载:下载地址。
致谢:基础框架来源BoW,开发版本在此基础上进行,已在Ubuntu、OS X上测试通过,Windows需要支持c++11的编译器(VS2012及其以上)。
使用
代码下载地址:bag-of-words-stable-version,这个是稳定版,上层目录里的开发版不要下载,那是我添加测试新模块所用的。
编译
修改Makefile文件,如果你的系统支持多线程技术,将
CFLAGS = -std=c++11
修改为
CFLAGS = -std=c++11 -fopenMP # if openMP accesses, using this
修改完上面后,再修改编译所需的OpenCV和cppsugar,即
INCPATH = -I/usr/local/include -I/Users/willard/codes/cpp/opencv-computer-vision/cpp/BoVW/cppsugar
LIBPATH = -L/usr/local/lib
/usr/local/include和/usr/local/lib分别是OpenCV所在的包含头文件目录路径和库目录路径,修改为你本机所在的目录即可。后面的cppsugar目录同样换成你本机的目录。
修改。这些修改完成后,执行下面命令进行编译:
make
编译后即可在所在目录生成可执行文件。
生成图库列表文件
对于待检索的图像库imagesDataSet,执行下面命令
python imgNamesToTXT.py -t /Users/willard/Pictures/imagesDataSet
上面执行后生成一个imageNamesList.txt的文件,该文件中包含的是每幅图像的路径及其图像文件名。
建立索引
执行下面命令,会完成特征提取、生成词典、量化生成bag of word向量:
./index imageNamesList.txt
上面命令执行玩,会生成两个文件bows.dat和dict.dat,分别存放的是图像库每幅图像的bag of word向量以及词典。
查询图像
按下面命令进行查询
./search /Users/willard/Pictures/first1000/ukbench00499.jpg imageNamesList.txt
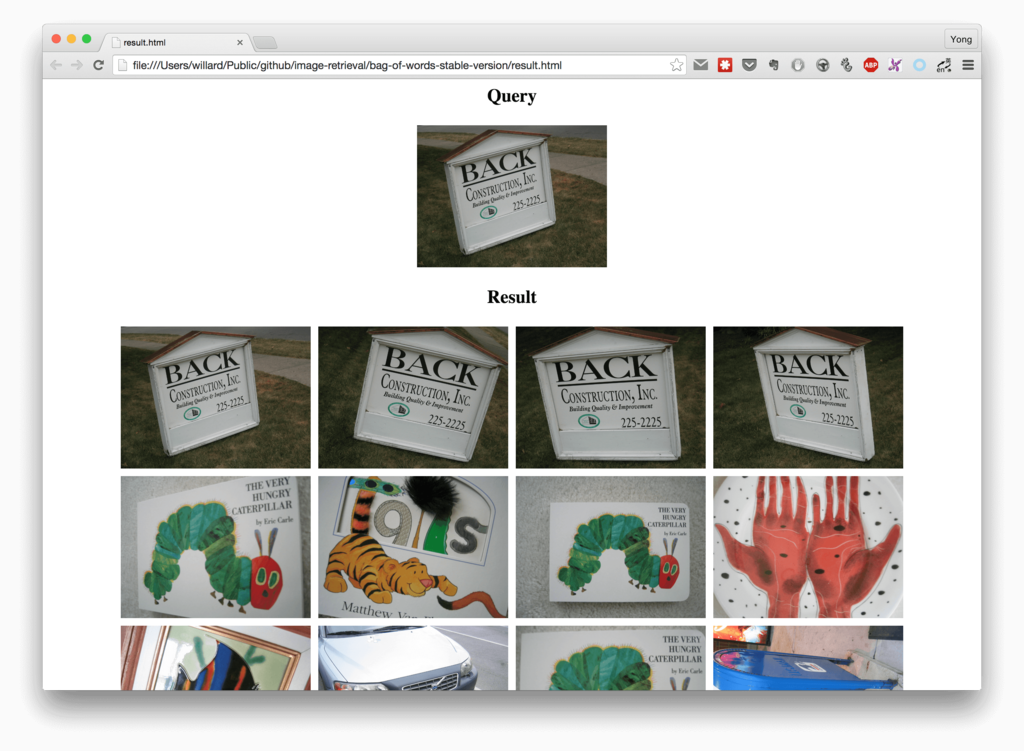
其中/Users/willard/Pictures/first1000/ukbench00499.jpg是查询图像,执行完后,会生成一个result.html的文件,应为要显示检索结果,所以这里采用的是用html页面的方式显示检索结果的,用浏览器打开即可。
批量测试
为了评价检索的效果,可以使用ukbenchScores.cpp计算在ukbench图像库上的NS score(NS分数),下面是在ukbench1000张图像上计算的NS score:
Ukbench first 1000 images, the NS-scores: 3.358, with tf*idf and histogram intersection kernel distance.
Ukbench first 1000 images, the NS-scores: 3.602, with tf and histogram intersection kernel distance.
注意,该框架中采用的相似性度量方式是直方图相交(histogram intersection kernel)的方法,测试发现直方图相交的方法要比用余弦距离度量的方式效果更好,但计算速度较慢。
开发版本bag-of-words-dev-version中加入了逆文档词频以及RANSAC重排,待效果达到预期后,会添加到稳定版中。